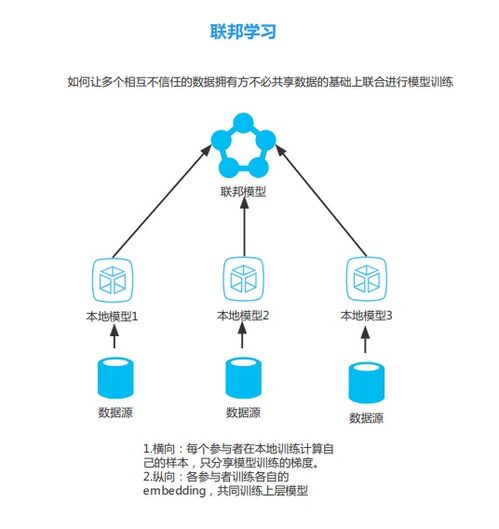
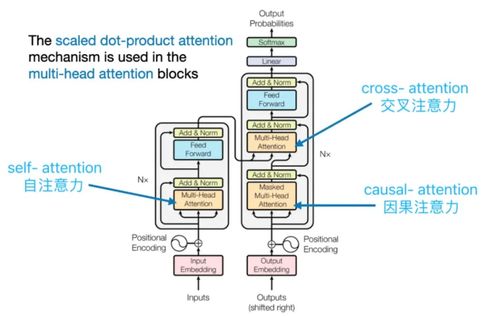
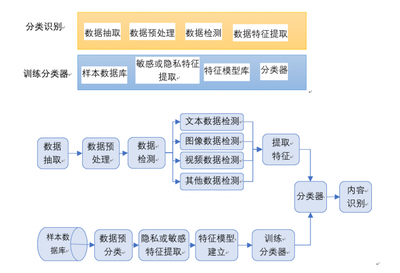
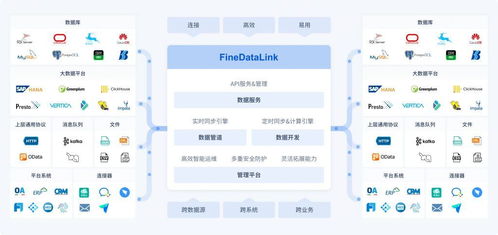
数据预处理是数据分析和机器学习中的一个关键步骤,它直接影响模型的性能和结果的准确性。在Python中,数据预处理通常使用pandas、numpy和scikit-learn等库进行。本文将从实践角度探讨几种常见的Python数据预处理技术,帮助开发者高效处理原始数据。
数据清洗是预处理的基础阶段。这包括处理缺失值、检测异常值和删除重复记录。例如,使用pandas的dropna()可以删除含有缺失值的行,或用fillna()用均值或中位数填充缺失值。对付异常值,可以使用IQR(四分位距)方法过滤出不合理的高亮数据,并通过可视化工具如matplotlib或seaborn辅助识别。
数据变换是确保数据格式和结构统一的关键,涉及归一化与标准化。标准化通过Z-Score计算使数据均值为0、标准差为1,常用scikit-learn的StandardScaler实现。归一化如Min-Max Scaling则将数据缩放到固定范围[0,1],利于深层模型的收敛。变换还包括对数变换来减小偏态数据和二进制化等操作场景。”