数据治理是组织有效管理、保护和利用数据资产的关键框架,而数据处理技术是支撑这一框架的七大核心技术之一,是数据从原始状态转变为可用资产的核心环节。全面了解数据处理技术,对于构建坚实的数据治理体系至关重要。
数据处理技术是指在数据治理过程中,对数据进行采集、清洗、转换、集成、存储和加工的一系列技术方法与工具的总称。它确保了数据的质量、一致性、可用性和安全性,为数据分析、挖掘与应用提供可靠的基础。其核心目标是将原始、分散、多源、异构的数据,转化为统一、准确、可信、易于访问的高质量数据资源。
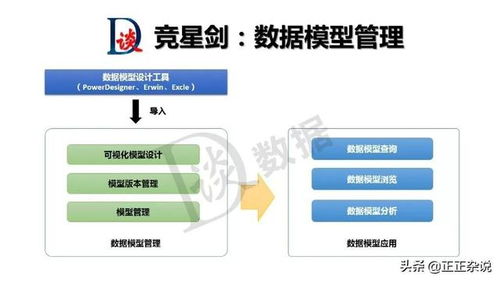
在数据治理的语境下,数据处理技术主要包括以下几个关键方面:
- 数据采集与获取:这是数据处理的起点。技术包括批量数据抽取(如ETL工具)、实时数据流采集(如Kafka、Flink)、网络爬虫、API接口调用等。治理重点在于定义数据源、确保采集的合规性、完整性和及时性。
- 数据清洗与质量提升:旨在识别并纠正数据中的错误、不一致、重复和缺失值。关键技术涉及数据剖析(发现质量问题)、数据标准化、数据匹配与去重、异常值检测与处理等。这是提升数据可信度的核心步骤,直接关联到数据质量管理的成效。
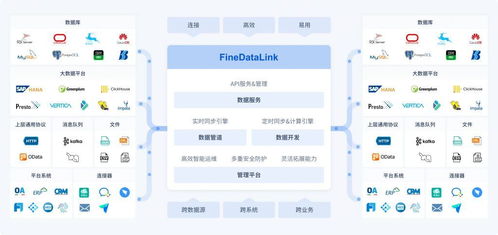
- 数据转换与集成:将来自不同源系统、不同格式的数据进行转换和整合,形成统一、一致的视图。包括数据格式转换、代码值映射、数据聚合、数据关联(Joins)以及主数据管理(MDM)技术。数据虚拟化技术也在此范畴,它能在不移动数据的前提下提供集成视图。
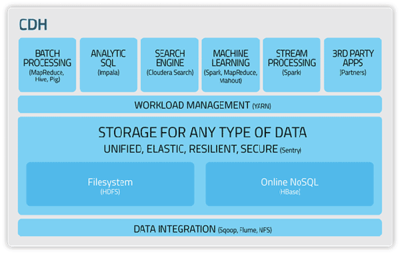
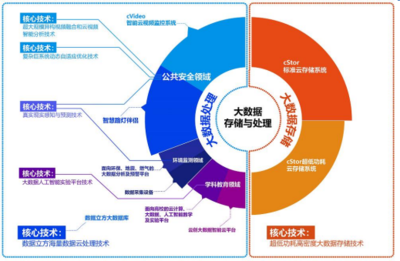
- 数据存储与管理:为处理后的数据提供合适的存储方案。技术选型需考虑结构化数据(关系型数据库)、半结构化/非结构化数据(NoSQL数据库、数据湖、对象存储)、以及支持大规模分析的分布式存储(如HDFS)。数据分层存储(原始层、清洗层、聚合层、应用层)是常见的治理实践。
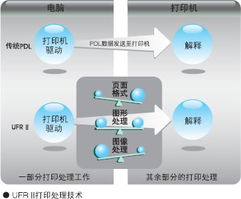
- 数据加工与计算:对数据进行进一步的聚合、计算和衍生,生成满足业务需求的数据集或指标。这包括批处理计算(如MapReduce, Spark)、实时流计算(如Storm, Spark Streaming)、以及交互式查询引擎(如Presto, Impala)。
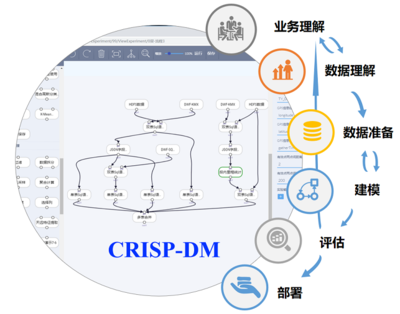
- 数据处理流水线与自动化:将上述步骤编排成可重复、可监控、可调度的自动化工作流。现代数据流水线工具(如Airflow, Dagster, dbt)和DataOps理念的实践,极大地提升了数据处理过程的效率、可靠性和可维护性,是数据治理运营化的重要体现。
数据处理技术在数据治理中扮演着“引擎”的角色。它不仅是执行数据质量规则、实施数据标准、保障数据安全与隐私(如数据脱敏、加密)的技术载体,更是实现数据资产价值释放的必经之路。一个组织的数据处理能力,直接决定了其数据治理的落地深度和业务价值的产出效率。
因此,在规划和实施数据治理时,必须将数据处理技术作为核心能力进行建设,选择与业务目标、数据规模和技术生态相匹配的技术栈,并建立相应的流程与规范,确保数据处理活动本身也处于有效的治理之下,从而形成从数据到价值的良性闭环。