Transformer模型凭借其在自然语言处理等领域的卓越表现,已成为人工智能领域的核心架构。其成功背后,高效且强大的数据处理技术功不可没。本文将通过动画演示的视角,深入浅出地解析支撑Transformer高效运行的四大数据处理关键技术。
1. 分词与词嵌入(Tokenization & Embedding)
数据处理的第一步是将原始文本(如句子、段落)转化为模型可以理解的数字形式。这一过程首先通过分词技术,将连续的文本切分成有意义的单元(如单词、子词)。通过词嵌入层,将这些离散的符号映射为高维空间中的连续向量。这个向量不仅包含了词汇的语义信息,还为其在模型中的计算奠定了基础。动画可以生动展示一个句子如何被拆分成一个个Token,并像查表一样转换为一个个富含语义的向量。
2. 位置编码(Positional Encoding)
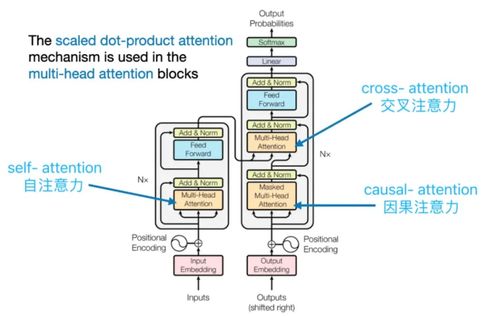
Transformer模型摒弃了循环神经网络(RNN)的顺序结构,其自注意力机制本身不具备感知单词顺序的能力。因此,位置编码技术至关重要。它通过为每个词向量添加一个包含其位置信息的独特向量,将序列的顺序信息显式地注入模型。常用的方法是使用正弦和余弦函数来生成这些位置向量。动画可以形象地展示这些如同“波纹”或“条形码”的位置向量是如何逐位叠加到词嵌入向量上,让模型“知道”每个词在句子中的先后次序。
3. 掩码(Masking)
在训练过程中,尤其是在处理序列生成任务(如机器翻译、文本摘要)时,模型需要遵循“不能偷看未来信息”的原则。掩码技术在此扮演了关键角色。它通过在注意力权重矩阵的上三角区域(代表“未来”的词)填充一个极大的负值(如负无穷),再经过Softmax函数后,这些位置的注意力权重几乎变为零,从而屏蔽了未来词对当前词的影响。动画可以清晰地演示一个注意力矩阵如何通过掩码操作,从全连接状态变为只关注当前位置及之前历史信息的“下三角”有效区域。
4. 批处理与填充(Batching & Padding)
为了充分利用GPU等硬件的并行计算能力,提高训练效率,模型通常同时处理多个样本,即批处理。一个批次内的文本序列往往长短不一。为了解决这个问题,填充技术被引入:将较短的序列末尾添加特定的填充符号(如[PAD]),使其长度与批次内最长的序列保持一致,从而形成一个规整的张量。在计算注意力或损失时,需要忽略这些填充符号的影响。动画可以展示不同长度的句子如何被“对齐”到同一长度,组成一个整齐的矩阵送入模型,以及注意力机制如何“忽略”那些填充部分。
分词嵌入、位置编码、掩码以及批处理与填充,这四大数据处理技术如同精密的齿轮,协同工作,为Transformer模型提供了结构规整、信息完备的输入数据,是其强大性能不可或缺的基石。通过动画形式的揭秘,这些看似复杂的技术原理变得直观易懂,让我们得以一窥现代深度学习模型高效运转背后的数据艺术。