在大数据处理的复杂流程中,数据预处理与数据处理技术扮演着至关重要的基石角色。原始数据往往充斥着噪声、缺失值、不一致和冗余信息,直接进行分析如同在沙土上建造高楼,结果必然不可靠。因此,数据预处理旨在通过一系列技术手段,将“脏数据”转化为高质量、可用于分析的“干净数据”,其核心目标是为后续的数据挖掘、机器学习与智能决策提供坚实的数据基础。
一、数据预处理的核心步骤
数据预处理是一个系统性工程,通常包含以下几个关键环节:
- 数据清洗(Data Cleaning):这是预处理的第一步,也是最耗时的一步。其主要任务是处理数据中的“脏”问题,包括:
- 处理缺失值:对于数据中的空白或无效记录,可采用删除法(直接删除缺失记录)、填充法(用均值、中位数、众数或通过模型预测进行填充)或插值法进行处理。
- 处理噪声数据:识别并平滑数据中的异常点或错误值,常用方法有分箱(通过考察数据的“近邻”来平滑数据值)、回归(通过拟合函数来平滑数据)和聚类(将类似的值聚集在一起以识别离群点)。
- 纠正不一致:统一数据格式、单位和编码,例如将日期统一为“YYYY-MM-DD”格式,或将“男/女”与“M/F”进行标准化。
- 数据集成(Data Integration):大数据往往来源于多个异构的数据源,如数据库、数据仓库、日志文件、传感器网络等。数据集成需要将这些来源不同、格式各异、标准不一的数据合并成一个一致的数据存储(如数据仓库或数据湖)。其关键技术包括实体识别(判断不同数据源中的记录是否指向同一现实实体)、冗余检测与处理,以及解决数据值冲突。
- 数据变换(Data Transformation):将数据转换成更适合挖掘的形式。常见变换包括:
- 规范化(Normalization):将属性数据按比例缩放,使之落入一个特定的区间(如[0,1]或[-1,1]),以消除不同特征量纲的影响。常用方法有最小-最大规范化、Z-score标准化等。
- 离散化(Discretization):将连续型属性值划分为若干区间,用区间标签或概念分层来替代实际数据值。例如,将年龄“连续值”离散化为“青年”、“中年”、“老年”。
- 属性构造:通过已有属性构造新的属性,以更好地刻画数据特征,提高后续分析的精度。例如,在零售数据中,由“单价”和“数量”构造“销售额”这一新属性。
- 数据归约(Data Reduction):大数据集往往规模巨大,直接处理成本高昂。数据归约旨在保持数据完整性的前提下,尽可能缩减数据规模,从而提高后续处理的效率。主要技术有:
- 维度归约(降维):减少所考虑的随机变量或属性的个数。主成分分析(PCA)和线性判别分析(LDA)是经典的降维技术,它们能够将高维数据投影到低维空间,同时保留最重要的数据变异信息。
- 数量归约:用替代的、较小的数据表示形式替换原始数据,例如通过抽样技术生成数据子集,或使用聚类、直方图等模型来代表数据。
- 数据压缩:使用编码机制(如小波变换)压缩数据,减少存储空间。
二、关键数据处理技术
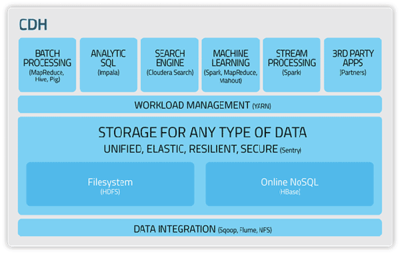
在预处理之后,高效的数据处理技术是驾驭海量数据的引擎。这些技术主要解决数据的存储、计算与查询问题。
- 分布式存储技术:
- Hadoop HDFS:作为Hadoop生态系统的基石,HDFS(分布式文件系统)采用主从架构,将大文件分割成块(Block)并分布式存储在集群的多个节点上,提供了高容错性和高吞吐量的数据访问能力,非常适合一次写入、多次读取的场景。
- 分布式计算框架:
- MapReduce:一种经典的编程模型,用于大规模数据集的并行运算。其核心思想是“分而治之”,将计算任务分为Map(映射)和Reduce(归约)两个阶段,非常适合处理离线批处理任务。
- Spark:相对于MapReduce基于磁盘的计算,Spark引入了弹性分布式数据集(RDD)概念,将中间结果缓存于内存中,使得迭代计算和交互式查询的性能提升了一个数量级。Spark Streaming、Spark SQL等组件也使其能够处理流数据和结构化数据查询。
- 流数据处理技术:
- 对于物联网、实时监控等场景产生的连续、无界的数据流,需要实时或近实时处理。Apache Storm、Apache Flink和Spark Streaming是主流的流处理框架。它们能够以低延迟处理持续流入的数据,并进行窗口聚合、事件模式检测等复杂计算。
- NoSQL与NewSQL数据库:
- 为应对大数据多样性(Variety)和高并发读写的挑战,突破了传统关系型数据库的限制。NoSQL数据库(如键值存储Redis、文档数据库MongoDB、列族数据库HBase、图数据库Neo4j)在数据模型和扩展性上更加灵活。而NewSQL数据库(如Google Spanner, TiDB)则试图在保持SQL和ACID事务特性的获得与NoSQL类似的水平扩展能力。
###
数据预处理与数据处理技术共同构成了大数据价值挖掘的“前处理车间”和“动力系统”。没有高质量的预处理,分析结果将失之毫厘,谬以千里;没有高效、可扩展的处理技术,海量数据的价值就无法被及时释放。随着数据规模的持续膨胀和应用场景的日益复杂,这两类技术仍在不断演进,与人工智能、云计算的结合也愈发紧密,持续推动着大数据产业向更深、更广的领域迈进。