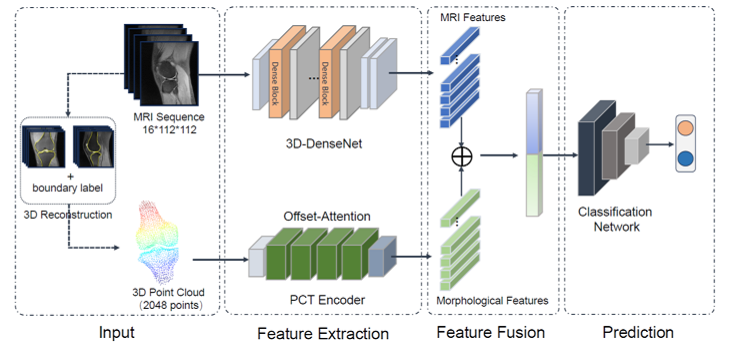
随着人工智能与大数据应用的深入,非结构化数据处理需求激增,向量数据库作为高效管理高维嵌入向量的核心技术,已成为现代数据基础设施的关键组件。星环科技旗下的Transwarp Hippo向量数据库,在1.1版本中实现了多项重磅特性升级,旨在从性能、成本、易用性及可靠性等多个维度,为用户提供更强大的数据处理能力,切实推动业务实现“降本增效”的目标。
一、核心性能跃升,处理效率倍增
Transwarp Hippo 1.1在查询与索引构建性能上实现了显著突破。通过底层算法优化与并行计算框架的增强,对于大规模向量数据的近邻搜索(ANN)任务,其查询延迟大幅降低,吞吐量显著提升。新版本支持更高效的索引类型与混合查询,使得在十亿甚至百亿级别的向量数据集中进行毫秒级检索成为可能。这意味着企业能够在更短的时间内从海量图像、视频、文本或音频数据中提取关联信息,加速推荐系统、智能检索、欺诈检测等AI应用的响应速度,直接提升业务运营效率。
二、存储与计算成本优化,实现精细化资源管理
“降本”是本次升级的核心着力点之一。Hippo 1.1引入了更智能的数据压缩与分层存储机制。通过先进的量化算法和选择性编码技术,在保证查询精度可控的前提下,有效压缩向量数据存储空间,降低存储成本高达30%-50%。其计算资源调度器得到增强,支持根据工作负载动态调配CPU、内存及GPU资源,避免资源闲置与浪费。用户可以为不同的业务场景(如离线的索引构建与在线的实时查询)配置差异化的资源策略,实现计算成本的最优化。
三、增强的易用性与生态集成,降低开发与运维门槛
新特性极大地提升了开发者的体验与运维管理效率。Hippo 1.1提供了更丰富的API接口和与主流深度学习框架(如TensorFlow、PyTorch)以及数据平台(如Spark、Flink)的无缝连接器,使得向量数据的生成、导入、查询与分析流程能够轻松嵌入现有数据管道。增强的图形化管理界面与监控告警功能,让集群状态、性能指标、查询热点一目了然,简化了日常运维的复杂度,减少了企业在专业运维人力上的投入。
四、企业级可靠性与可扩展性保障
为满足大规模生产环境的需求,Hippo 1.1强化了其企业级特性。它支持跨数据中心的高可用部署与容灾备份,确保服务持续在线。其分布式架构具备线性扩展能力,可通过简单地增加节点来应对数据量与并发请求的增长,保护企业初始投资。增强的数据安全特性,如细粒度访问控制与审计日志,确保了敏感向量数据在存储与使用过程中的安全合规。
五、赋能多元场景,释放数据潜能
综合这些新特性,Transwarp Hippo 1.1能够更出色地服务于诸多前沿应用场景:
- 智能媒体管理:快速在海量图库或视频库中进行以图搜图、内容去重与版权追踪。
- 个性化推荐与广告:基于用户与商品的高维向量表征,实现实时、精准的相似推荐。
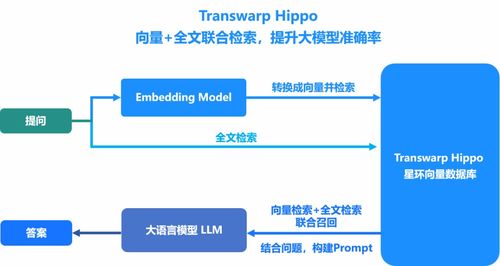
- 大模型增强:充当大模型的外部知识库(RAG),提供快速、准确的知识检索,减少幻觉,提升问答质量。
- 生物信息学与化学研究:高效比对分子结构或基因序列的向量表示,加速新药发现与材料研究。
Transwarp Hippo 1.1向量数据库的迭代升级,并非仅是功能的堆砌,而是围绕“降本增效”核心目标进行的系统性工程。它通过提升处理性能、优化资源利用、简化操作流程和夯实系统根基,为企业构建高效、经济、易用的下一代AI数据底座提供了强有力的支撑,助力企业在数据驱动的竞争中挖掘更深层的价值,赢得先机。