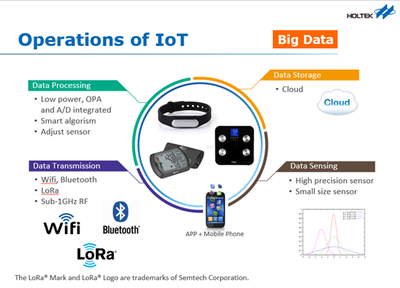
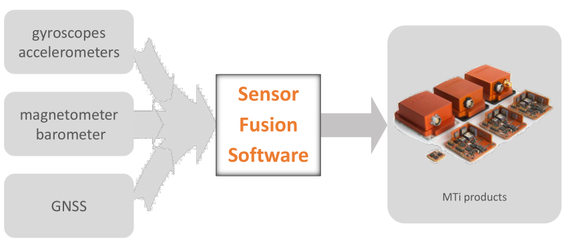
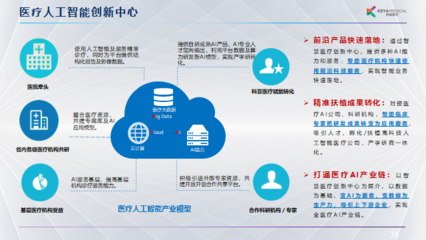
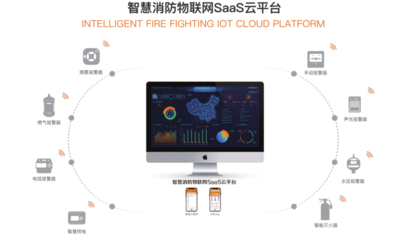
随着数字化时代的到来,大数据已成为各行各业的核心竞争力。学习大数据不仅需要掌握基础理论知识,还需精通一系列数据处理技术。本文将系统介绍大数据学习的核心内容,重点解析数据处理技术的应用与实践。
一、大数据基础理论知识
- 大数据概念与特征:理解大数据的5V特性(Volume、Velocity、Variety、Veracity、Value),了解大数据生态系统的发展历程。
- 分布式系统原理:掌握分布式计算、存储的基本概念,理解CAP定理、一致性模型等核心理论。
- 数据仓库与数据湖:区分传统数据仓库与新兴数据湖架构,了解各自的适用场景和优缺点。
二、数据处理技术体系
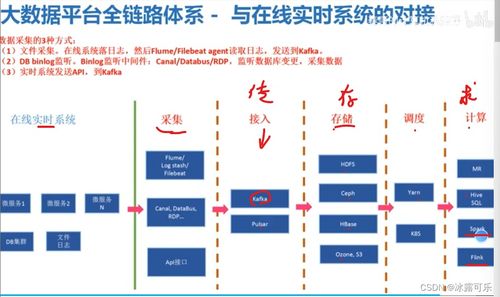
- 数据采集与集成
- 批量数据采集:Sqoop、DataX等工具的使用
- 实时数据流采集:Flume、Kafka等消息队列技术
- 数据同步与ETL流程设计
- 数据存储与管理
- 分布式文件系统:HDFS原理与运维
- NoSQL数据库:HBase、Cassandra、MongoDB等
- NewSQL数据库:TiDB、ClickHouse等
- 数据分区、分片与副本策略
- 数据处理与计算
- 批处理框架:MapReduce编程模型、Spark Core
- 流处理技术:Spark Streaming、Flink、Storm
- 图计算框架:GraphX、Giraph
- 内存计算与优化技术
- 数据查询与分析
- SQL-on-Hadoop工具:Hive、Impala、Presto
- 交互式查询引擎:Druid、Kylin
- 数据可视化与报表工具
- 数据治理与质量
- 元数据管理:Atlas、DataHub
- 数据血缘分析
- 数据质量监控与校验
- 数据安全与权限管理
三、大数据平台与架构
- Hadoop生态系统:掌握HDFS、YARN、MapReduce等核心组件
- 云原生大数据平台:了解在Kubernetes上部署大数据组件的实践
- 混合架构设计:Lambda架构与Kappa架构的比较与选择
四、实践技能要求
- 编程语言:熟练掌握Java、Scala、Python等语言
- Linux系统操作:熟练使用Shell脚本进行系统管理
- 容器化技术:Docker、Kubernetes的部署与管理
- 监控与调优:集群性能监控、故障排查与优化
五、进阶学习方向
- 机器学习与人工智能:Spark MLlib、TensorFlow等框架
- 实时推荐系统架构
- 数据湖仓一体化趋势
- 数据中台建设方法论
大数据学习是一个系统工程,需要从理论基础到技术实践全面掌握。数据处理技术作为核心环节,既需要理解各种框架的原理,又要具备实际部署和优化的能力。随着技术的不断发展,大数据从业者还需要保持持续学习的态度,紧跟技术演进趋势,才能在数据驱动的时代保持竞争力。